

From left to right: Low-resolution, L1 loss, MSE loss, and Ground truth image
Results
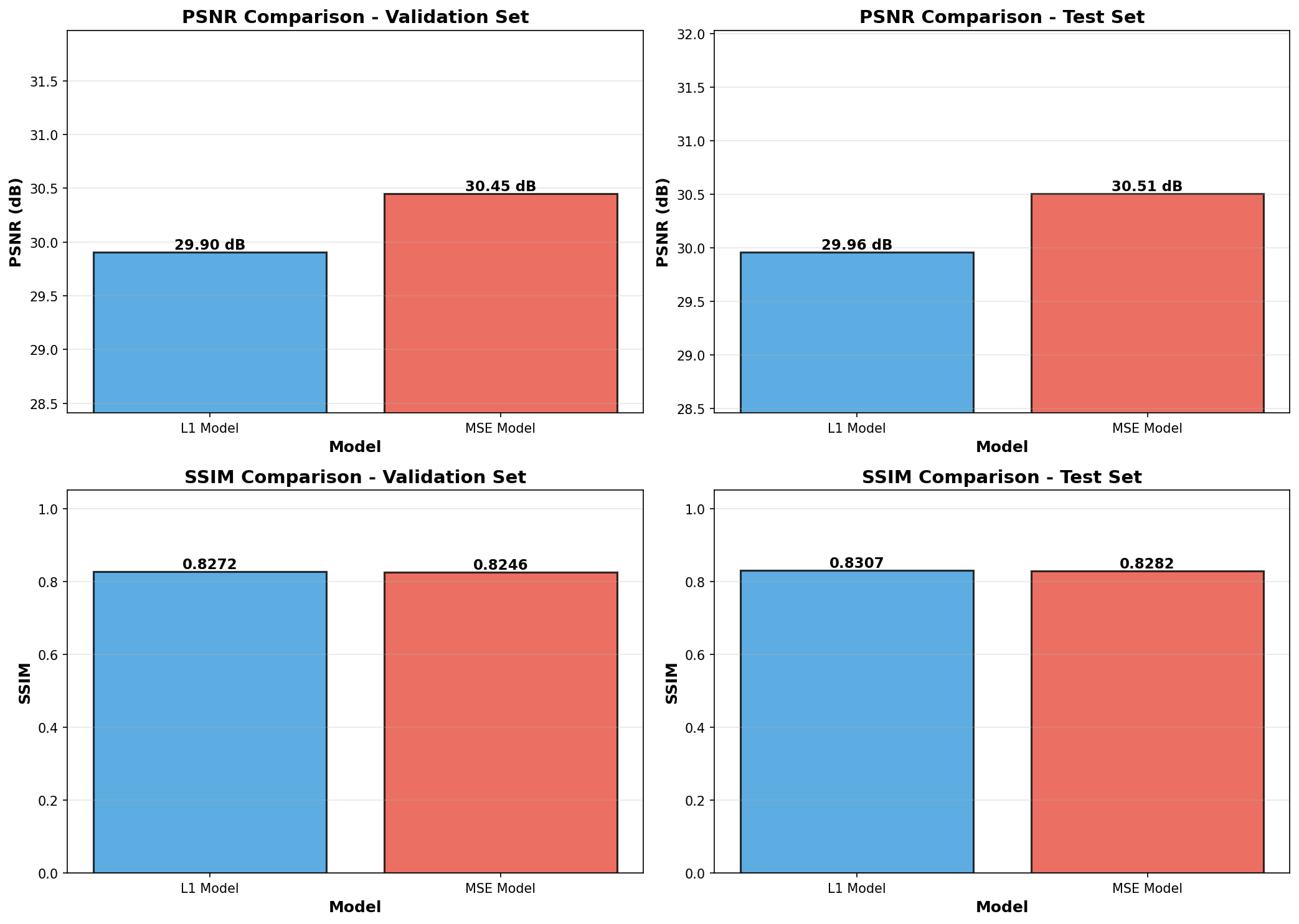
In order to evaluate the models, two main metrics were used: PSNR, which measures pixel-perfect mathematical accuracy, and SSIM, which measures perceived structural similarity (how a human views)
The result of the model comparison shows a trade-off between the two metrics:
-
PSNR (Peak Signal-to-Noise Ratio): measures the mathematical calculation of pixel values. The higher PSNR means the reconstructed image is closer to the original in terms of raw pixel similarity.
The MSE-trained model won on PSMR, as expected. This model was more optimized to minimize the exact mathematical error that PSNR is based on.
-
SSIM (Structural Similarity Index): evaluates perceived visual quality by comparing textures, structure, and contrast. The better SSIM indicates the image looks more natural and true to human vision.
The L1-trained model won on SSIM, as expected. This model performs a better job at recreating the sharp structures, edges, and textures that a human eye perceives as a high-quality image.
Model Architecture
- Initial Feature Extraction: a single convolutional layer reads the input image and extracts its initial low-level features.
- Deep Feature Learning: A series of 8 residual blocks. Using residual connections enhance the performance, as it allows the network to go very deep to learn complex features without suffering from the vanishing gradient problem.
- Efficient Upsampling: Instead of using a traditional transposed convolution, nn.PixelShuffle layer was used. This layer first increases the number of channels and then intelligently shuffles them into the spatial dimensions, resulting in a clean, high-quality upscale.
Training Process
Training Configuration
Dataset
Trained on a large dataset of high-resolution images with various downsampling factors.
Optimizer
Used Adam optimizer with learning rate scheduling for stable convergence.
Batch Size
Optimized batch size for memory efficiency while maintaining training stability.
Training Epochs
Trained for multiple epochs with early stopping to prevent overfitting.
Training Process
Choosing L1 Loss
A key decision was the choice of loss function. While the common MSE (L2) Loss is easy to optimize, it heavily penalizes large errors, which forces the model to learn a safe blurry average.
I hypothesized that L1 Loss (Mean Absolute Error) would serve a better performance. L1 is less sensitive to outliers and is known to encourage the preservation of sharp details and realistic textures, the goal of super-resolution.
Training
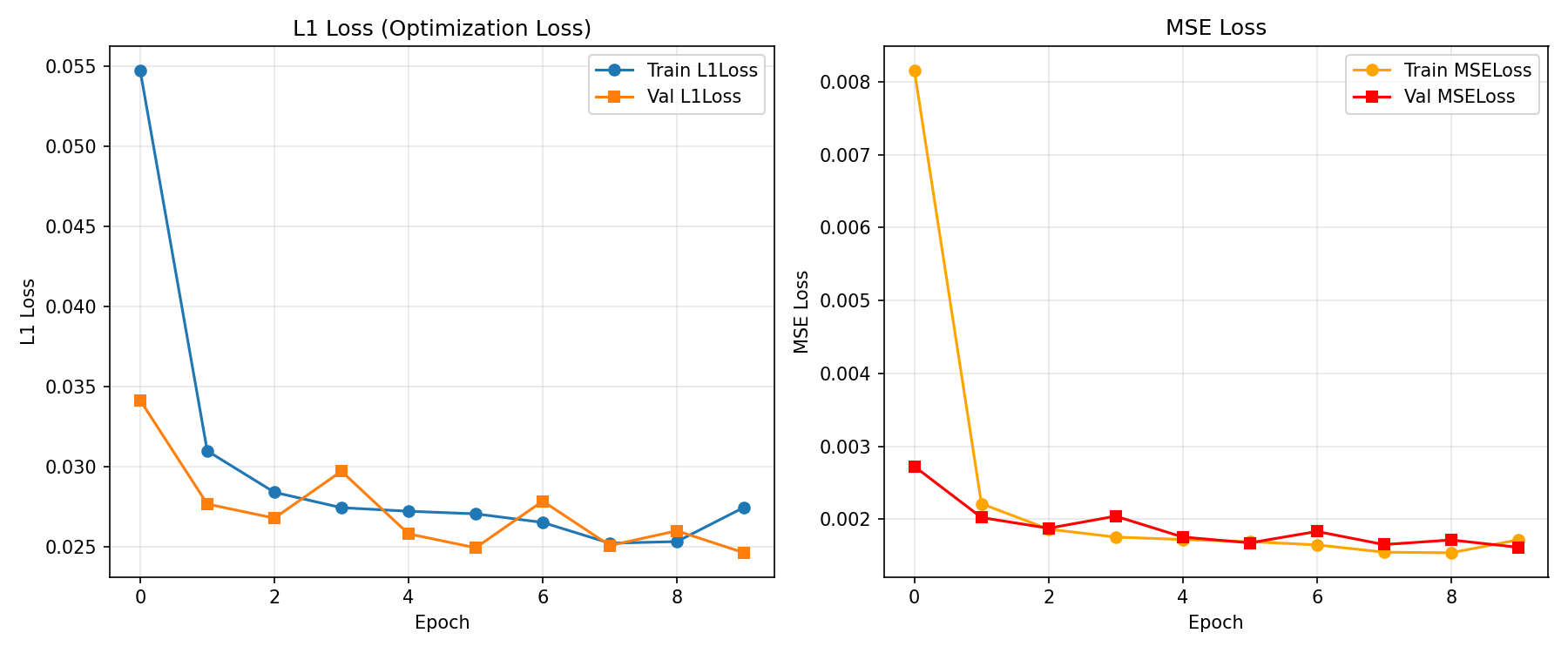
The training and validation loss curves (for both L1 and MSE) confirm the models are healthy. The loss consistently decreases (convergence) and the small gap between the train (blue/orange) and val (green/red) lines shows that the models are not overfitting.
Proof of the Hypothesis
The loss curves show the models learned, but they don't prove which model is better. To achieve this, I evaluated both the L1-trained model and a MSE model against the entire test set using two metrics.
PSNR vs SSIM
| Evaluation Metric | L1-Optimized Model | MSE-Optimized Model | Winner |
|---|---|---|---|
| PSNR (dB) ↑ (Measures mathematical accuracy) |
29.96 | 30.51 | MSE Model |
| SSIM ↑ (Measures perceived structural quality) |
0.8307 | 0.8282 | L1 Model |
The MSE-trained model won on PSNR, which was expected as PSNR is an MSE-based metric.
However, L1-trained model won on SSIM (Structural Similarity Index). This proves that the L1-trained model does a superior job at the goal: recreating the sharp structures and details that a human eye perceives as a high-quality image.
Future Applications
This project's findings have direct implications for critical fields like medical imaging. In a diagnostic setting, a model that produces a blurry, mathematically safe average (high PSNR) is dangerous.
It could smooth over the very details that are critical for a diagnosis. This project provides a quantitative evidence that optimizing for L1/SSIM is the correct approach, such as a hairline fracture or the sharp boundary of a small tumor. This work validates a clear path for developing more reliable and perceptually-accurate models for healthcare.
Project Links
Project is still in improvement. Please check back soon for updates.